随着人工智能技术的不断发展,构建高效、专业的AI知识库成为企业和开发者的重要需求。RAGFlow作为一个功能强大的开源工具,提供了从数据处理到知识存储的完整解决方案,即使是零基础用户也能快速上手并精通。本文将详细介绍RAGFlow的核心功能、数据处理方法、存储服务机制,以及从入门到精通的完整学习路径。
RAGFlow是什么?RAGFlow是一款基于检索增强生成(Retrieval-Augmented Generation, RAG)技术的开源工具,旨在帮助用户构建智能知识库系统。它集成了数据预处理、向量化检索和生成式AI响应功能,支持多种数据源,包括文本、PDF、图像等。对于初学者来说,RAGFlow的安装过程非常简单,通常只需几个命令即可完成部署,例如使用Docker容器化技术,无需深入编程基础也能快速启动。
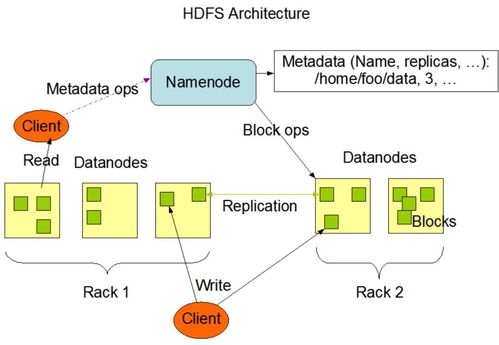
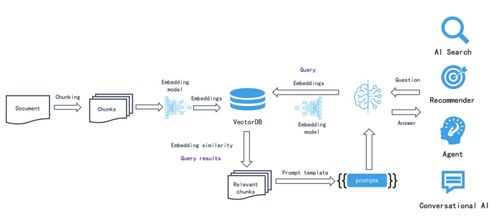
在数据处理方面,RAGFlow提供了强大的数据导入和预处理能力。用户可以将本地文件、数据库或通过API上传的数据源导入系统。RAGFlow会自动进行数据清洗、格式转换和内容提取,例如从PDF文档中提取文本、识别图像中的文字等。同时,工具内置了智能切分和向量化引擎,将文本数据转换为高维向量,便于后续的语义检索。这一步是构建知识库的核心,RAGFlow通过优化算法确保数据处理的准确性和效率,即使面对大规模数据也能保持高性能。
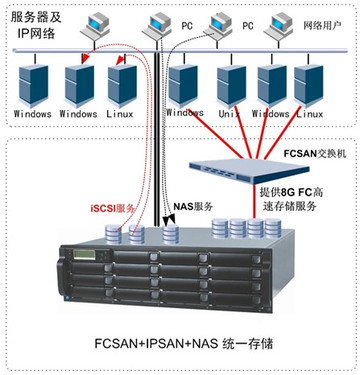
存储服务是RAGFlow的另一大亮点。系统支持多种后端存储选项,包括本地文件系统、云存储(如AWS S3、阿里云OSS)以及向量数据库(如FAISS、Milvus)。用户可以根据需求选择合适的存储方案,确保数据的可扩展性和安全性。RAGFlow还内置了版本控制和备份功能,帮助用户管理知识库的历史变更,防止数据丢失。通过RESTful API,用户可以轻松集成RAGFlow到现有系统中,实现动态数据更新和实时查询。
从零基础到精通的学习路径可以概括为以下几个步骤:第一步,安装和配置RAGFlow,熟悉其基本界面和功能模块;第二步,学习数据导入和预处理技巧,包括如何处理不同类型的数据源;第三步,掌握向量检索和生成模型的调优方法,例如调整相似度阈值和生成参数;第四步,深入存储服务配置,学习如何优化性能和安全性;通过实际项目应用,如构建企业FAQ系统或智能客服知识库,来巩固技能。RAGFlow社区活跃,提供详细的文档和教程,用户可以通过GitHub、论坛等渠道获取支持和进阶资源。
RAGFlow作为一个开源工具,降低了构建专业AI知识库的门槛。通过本文的介绍,希望读者能够快速掌握其核心功能,从数据处理到存储服务的全流程操作。无论是开发者还是业务人员,都能利用RAGFlow提升工作效率。赶紧收藏这篇文章,随时参考,开启你的AI知识库之旅吧!